At CloverDX, whether we’re talking to prospective new customers or to existing clients, we often hear the same problems from people trying to maintain and improve their data architecture.
Despite the differences in company sizes, industries, or the data goals they’re trying to achieve, it’s revealing that the pains people suffer are often very similar.
And these specific problems are usually indicators of larger, business-critical issues – the company’s losing money or making bad investment decisions, or someone’s embarrassing themselves in front of the board with incorrect data.
We thought we’d dive into some of these common symptoms people have told us, and share what the diagnosis (and treatment) might be.
So if any of these strike a chord with you, here’s what you can do about it….
The diagnosis: Your data processes are too big
The symptoms:
"Our stored procedures are too complex, and the person who wrote them has left the company"
This is a very common complaint. Data workflows evolve over time, and can get so complex and involve so many workarounds that no one understands why or how something is working any more.
This is especially true when it’s all the work of one person, who maybe didn’t document things as thoroughly as they might, and they’ve now left the company. There inevitably comes a time when you need to update the process, and you can’t.
Probably because everyone is too scared to touch it in case it breaks.
"Our team of 4 developers is slow and can't work in parallel"
You’re wasting time (and money) because your development team can’t split up the tasks they need to do to work efficiently.
"We forgot to implement auditing and we don’t know how to add it to the existing process"
If you’re just thinking about the 'data' part of your process, there’s a tendency to forget all the ‘other stuff’ that a robust process needs to include – the automation, orchestration and logging for example.
“Often after development of a new feature, our pipelines unexpectedly break”
Large, complex data jobs are really difficult to maintain well, and they’re really hard to cover with tests. Things breaking when you make changes are a common sign that your architecture could use some improvement.
The treatment: Break down your jobs into smaller pieces
Large jobs are one of the most typical signs of data architecture that needs improvement.
It’s really difficult to stay productive and efficient when you’re working on a single huge chunk of code. It’s hard to read, hard to understand, and hard to extend and test.
The remedy is to break complex processes into smaller pieces, with each individual piece of the pipeline dealing with one single task or responsibility.
The goal here is to identify pattens in your workflows so you can create reusable, repeatable pieces.
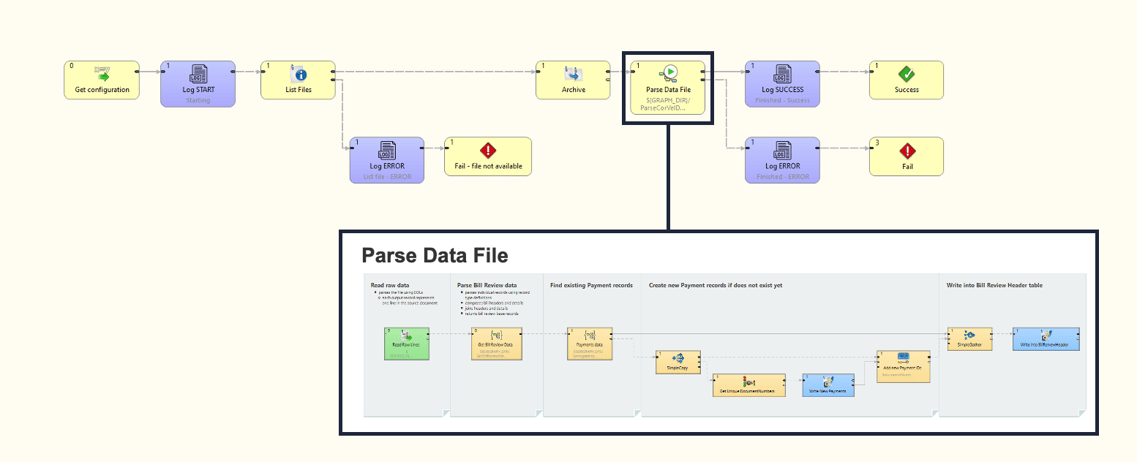 This is what that looks like in a data workflow in CloverDX. Notice how the one box actually opens up into a whole other layer of functionality hidden behind it. Having less than 10 steps in each design helps users understand and maintain the process.
This is what that looks like in a data workflow in CloverDX. Notice how the one box actually opens up into a whole other layer of functionality hidden behind it. Having less than 10 steps in each design helps users understand and maintain the process.
Benefits of breaking down your data processes:
- Easier to understand (especially for people who weren’t the ones who built it)
- Easier to perform unit tests on smaller pieces and individual simple pipelines
- Easier to parallelize work for better efficiency of your dev team
- Easier to reuse functionality, saving time and standardizing procedures for better consistency
The diagnosis: You’re reinventing the wheel and wasting time (and money)
The symptoms:
“Implementing a single change to our core process required updates to nearly 80 jobs”
If you have 80 data sources, but you’ve got a process that’s the same for all of those sources, you don’t need 80 data workflows.
“During an internal audit, we realized that our auditing components do not log at the same level”
When you’re building everything from scratch every time, you’re bound to end up with differences in how each process works. Implementing something like auditing functionality in different ways throughout a complex pipeline can lead to errors and confusion.
The treatment: Design in a modular way to avoid duplicating functionality
Reusing what you’ve already built saves time and improves consistency. And by creating ‘modules’ that you reuse across your pipelines, you make it far easier to be flexible and adapt pipelines without having to reinvent the wheel to build an entirely new process.
For example, if you want to swap a data source and you’ve built your pipeline in a modular way, then you don’t need to build an entirely new pipeline, you can just plug in the new source – and crucially you won’t need to touch the rest of the pipeline, resulting in significant time and cost savings.
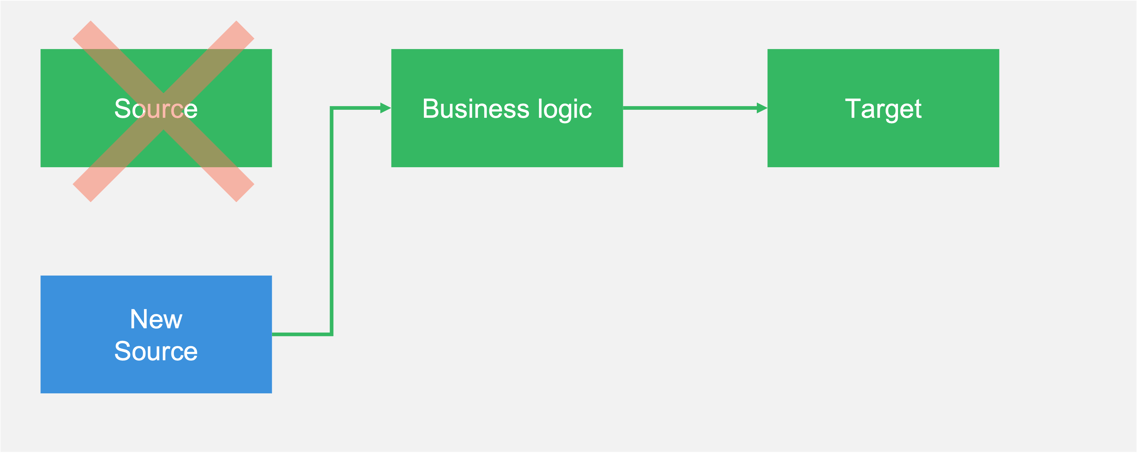 Swapping a data source - without having to touch the rest of the existing data pipeline
Swapping a data source - without having to touch the rest of the existing data pipeline
This also works the other way round too - you can take a source from one pipeline and plug it into another pipeline. This can be especially useful if you've already done work on that source, such as data quality checks, validation, or aggregations. Instead of doing all that all over again, we can reuse what we've already built in a new process:
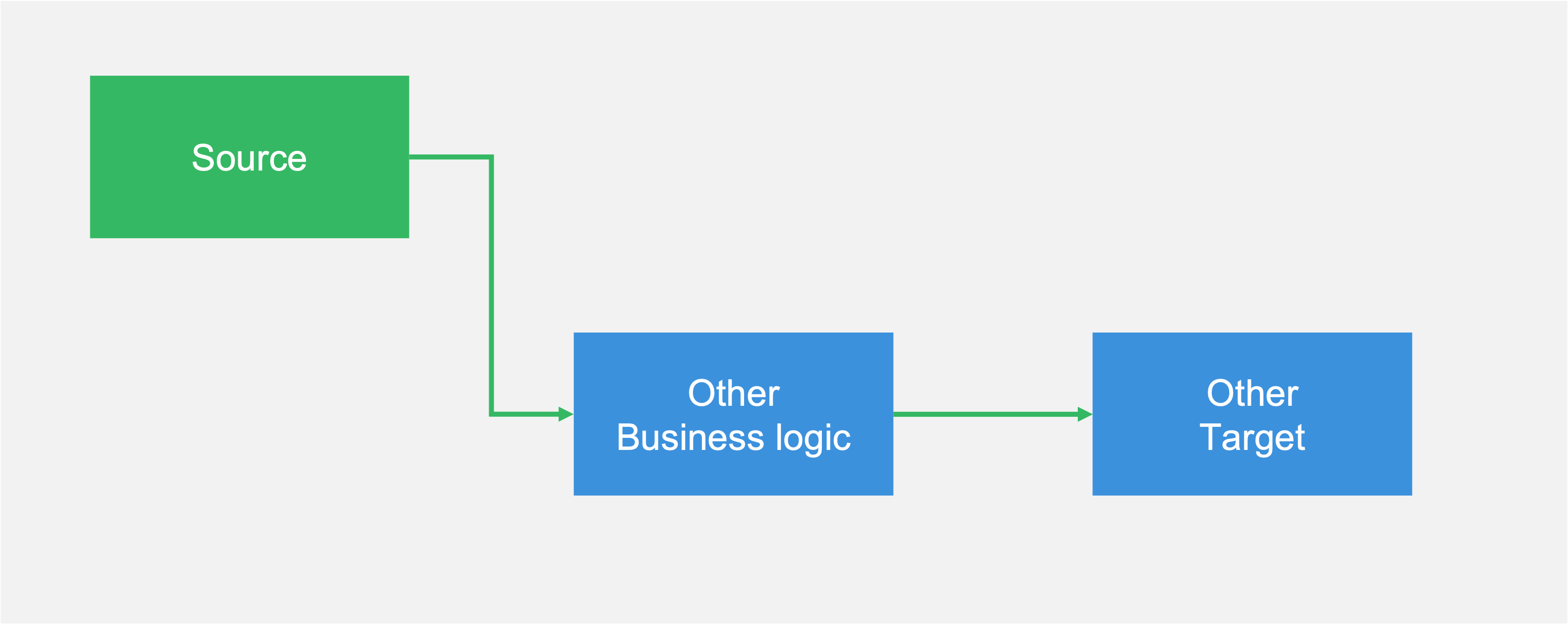 Taking the same data source as above, and plugging it into a new data pipeline
Taking the same data source as above, and plugging it into a new data pipeline
Benefits of good modular design and reusing components:
- Less developer time wasted on duplicating work
- Faster turnaround for changes in pipelines
- Standardization of processes across processes, pipelines and projects
- Better scalability
The diagnosis: You don’t have any consistency in your processes
The symptoms:
“Some data fields aren’t populated although the data is in the source”
The only thing worse than knowing your data is wrong, is when you don’t know it’s wrong.
This customer who came to us only discovered that their data had errors months down the line, which had already resulted in some bad decisions, and resulted in a costly process to fix it all retrospectively.
“Before each release we spend days fixing the conflicts when all the teams deliver their work”
A lack of development conventions and not having a good process for collaboration is bad for efficiency and productivity, and slows down delivery of your projects.

“Each developer approaches the task differently and the jobs are difficult to monitor in production”
For anyone monitoring jobs in production, it’s important to be able to see and understand what’s happening in the pipelines. When each developer tackles problems differently, it makes troubleshooting – as well as extending and maintaining your jobs – very difficult.
The treatment: Define conventions to enforce consistency
Defining conventions right across your data processes helps build consistency. From naming conventions for files and processes, conventions for documentation, and for development (where you should also have a solid approach to versioning and teamwork) – all can help increase productivity and make data flows easier to understand.
Benefits of striving for consistency:
- Makes data jobs more understandable across the whole organization, improving collaboration
- Helps prevent data quality issues downstream in the process
- Identify errors more easily, helping to meet SLAs
The diagnosis: Your data quality checks aren’t good enough
The symptoms:
“Because we didn’t check the dataset quality, we not only had to build another complicated clean-up process, but we were also running our business based on the wrong sales results”
Because of bad, inefficient or even completely missing data quality checks, business decisions can end up being based on incorrect information. No one wants to be responsible for wasting money, or presenting the company board with the wrong data.
“We can’t implement our new use case. We’ve identified an issue in the pipeline, but we can’t fix the data as we don’t store source data from our transactional systems.”
This client was getting data from their transactional system, but not storing it anywhere. So by the time they discovered the issues with their data, it was too late to be able to correct it as the original data was gone, meaning they were unable to deliver their project.
“Profiling a source helps us deliver better data, but the process is too slow and we can’t meet our SLA. Do we remove the data quality checks?”
If data quality checks are bottlenecking your process, the first question is often ‘should I just stop checking? The answer is typically ‘no’, but you should be thinking about how you can make things more efficient.
For example, in order to check the structure of an incoming file, one customer we spoke to was reading the entire file – not at all necessary - and changing the process to read just one line achieves the same outcome in a much smarter way.
The treatment: Build data processes that are robust enough to handle the (inevitable) poor data quality
Your data is going to be less-than-perfect, because this is real life. But by expecting that from the start, you can mitigate the impact. Validate early, do it in a smart way, reuse validation rules for consistency and efficiency, and back up data that you might need to fix any future issues.
Building data validation into your data ingestion processesBenefits of improving your data quality processes:
- More accurate data to support the business
- Fewer costs incurred in fixing critical issues
- Less risk from regulatory breaches or lost business
- More robust data pipelines
- Organization-wide efficiency and consistency from reusing validation rules
The long-term prognosis for your data architecture
The good news is that these common problems are all fixable. By implementing some best practices when developing your data architecture you can achieve some business-critical improvements:
- Saving money on development
- Improving the quality of, and trust in, your data
- Improving collaboration by making your data processes more understandable and consistent
If you’ve got any worrying symptoms with your data architecture that you want us to take a look at, just get in touch.
Share







