
Across all sectors, organizations are seeing a rapid increase in the amount of data they have to contend with. Therefore, being efficient with how you manage data is more important than ever.
Possessing the data is one thing, but having it in a workable state where you can apply analytics, migrate effectively and produce useful reports is another.
To do this, you’ll have to ingest it so it’s consolidated in one centralized location.
What is data ingestion?
Data ingestion involves taking data from an outside location and putting it into a specific system or process.
It’s a common challenge for businesses, as they often have to take client or customer data and move it to their own platform. From there, they can operate on it and return value back, by conducting data analysis or producing reports. In this scenario, the data comes from an outside source and so the format the data is in is going to be variable.
To deal with this challenge, and especially to deal with the challenges of working with different data sources and formats, organizations often have a lot of manual steps involved in the data ingestion process. This takes up a lot of time, particularly if it’s a recurrent ingest.
So, that’s a brief rundown of the process. But how do you make that data ingestion process faster, more reliable and easier to scale? By building a framework to automate it.
What are the objectives of a data ingestion process?
The objectives will vary from case to case, but often they include:
- Reducing burden. You want your data ingestion process to be as easy as possible for your clients or customers, without forcing them to use a specific format or spend a long time massaging their data for you.
- Empowering staff. Less technical staff members can operate and manage data with ease.
- Designing for resilience. You want a process that helps you handle variability in input formats, without having to rely on a development team.
- Automatically detecting new data. Once new data arrives, you can automatically set it into the pipeline.
- Orchestrating the entire process. Creates a complete process that works automatically to take the data all the way to the target system.
- Provide reporting. It helps you create robust reporting that provides actionable intelligence.
- Handling errors. Error reports support retries, so things will run smoother next time.
- Reusing pipelines. You can apply a reusable process for many different scenarios, so you won’t have to start from scratch with new clients.
CloverDX allows you to improve the rate at which you achieve these objectives by streamlining the ingest process. Often, the data you ingest has multiple formats and comes in from different sources. Data ingestion tools such as CloverDX can help you deal with complex data scenarios and work effectively with data that may need repurposing.
How setting up a data ingestion pipeline in CloverDX helps speed up customer data onboardingWhat does data ingestion look like in the real world?
Let’s take a look at a real-world scenario that uses an automated process, conducted with our data management platform, CloverDX. In this example, we’re working with schools to ingest their operational data for reporting.
The objective here was to allow customers to upload operational data so they could gain convenient, on-demand access to summarized and analyzed views. The operational data included enrolment, class schedules, contact information and attendance. Some of these datasets are dynamic and were likely to change day to day, so the ingest process needed to handle that velocity and variability.
The next step in designing this system was to ensure it could support data from multiple sources. It needed scalability, as well as ease of use. It had to support more schools, without necessarily using more people to complete the process.
Here are the stages for the initial process:
- Monitor primary source (FTP site) for incoming files.
- Monitor secondary source (email) for incoming files.
- Ingest
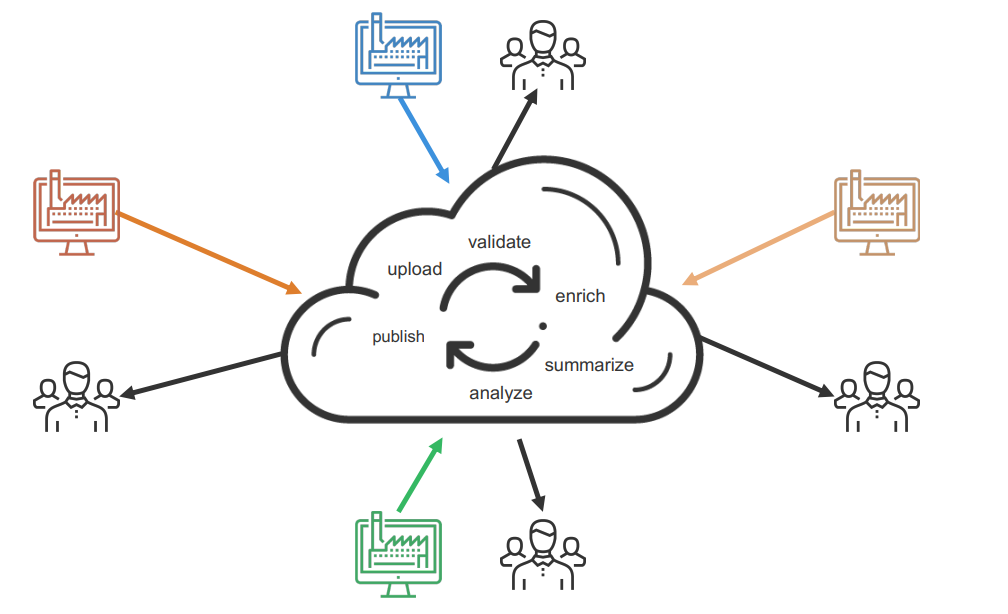
Ingesting has its own set of steps, which CloverDX can process in one pipeline. The steps go like this:
- Copy incoming files. The CloverDX pipeline will keep a lookout for incoming files and move them to a space where it can operate on them locally. It’ll skip files that aren’t interesting to the outcome.
- Unzip. Some files may come in a compressed format and will require unzipping. CloverDX will recognise this and unzip it automatically.
- Check manifest. CloverDX compares what it received versus what was expected. This is to check all necessary files are present. If not, the process will fail and it’ll notify the client that some information is missing.
- Profile. Quick sanity test to check data quality - is it the right format? Is it an empty file? Are there too many null values in key fields? Are there dates in the future that shouldn't be in the future? This stage helps prevent ingest failures.
- Transform. Additional transformations may be required for the ingest. Perhaps two fields need combining, or need splitting up into components. This is to account for the specific customizations of certain schools outside the generic pipeline.
- Load to target. Once files are validated or transformed and ready to go, it pushes them down to the target location. In this case, the next stage was copying to S3 and making an API call to an analysis engine.
- Log. Finally, CloverDX will produce a log detailing how everything went once the ingest is complete.
Fast, reliable and scalable data ingestion
Businesses are dealing with an increasing amount of data and need a smooth ingestion process to keep on top of it.
To speed up your ingestion and ensure your data is ready to scale, you’re going to need a powerful data management tool. CloverDX can orchestrate, compile and clean up your data as you ingest it, all in one powerful, visual tool.
Book a demo today to find out how CloverDX can help your business.
This blog is from our webinar: Making data ingestion faster, more reliable and easier to scale, which you can watch here.

Share







