
Your data has errors. That’s inevitable. But there are ways you can manage bad data.
The first important thing to realize is ‘don’t pretend your bad data isn’t there’. Instead, if you design bad data into your data architecture from the outset, you can avoid problems later on. And it’s not all bad news. Bad data can actually be a good thing in some situations - if you learn to treat it as an indicator of problematic areas in your business, and a driver for improvement.
1. What is bad data?
Bad data is an inaccurate set of information, including missing data, wrong information, inappropriate data, non-conforming data, duplicate data and poor entries (misspells, typos, variations in spellings, format etc).
There’s many reasons data can be rejected going through a process. From a typo or a missing reference during input validation, to a violation of business logic at some point along the pipeline, all the way through to an issue with pushing data to its target - any of these reasons and more can cause records to be rejected.
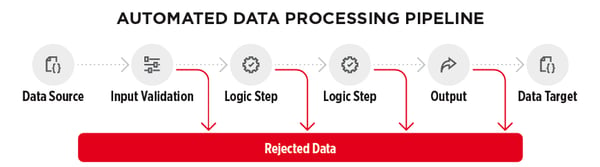
The impact of bad data on your data quality management process can vary depending on how many records get rejected. Missing records can affect downstream processes or analysis, or delay crucial operations such as deliveries or payments. In the worst case, bad data can cause the entire process to fail, leaving mess and inconsistencies behind in the systems involved.
The more efficiently your error handling system can deal with these rejected records and return them to the processing pipeline, the better your data (and therefore your business insight) becomes.

2. How can bad data be a good thing for your business?
Proactively building for and managing bad data, rather than trying to pretend it doesn’t exist, means that you can not only minimise the negative impact on your business, but can potentially pave the way for important business improvements too.
Proper visibility into the data correction process helps to understand the causes of bad data, and help to reveal other systemic problems that need to be addressed. Problems with your data can indicate the need for changes elsewhere in the process.
Changes in how data is sourced or processed, or how staff are trained for example, can often not only improve your data quality, but also improve efficiency, turnaround times and so directly impact business health.
Data errors can also provide insight into revenue leaks, showing you where you need to focus attention to fix problems that affect the bottom line.
3. Why is an error management process important?
Building an efficient error handling process into your data management brings many benefits:
- Automating error handling can help get (corrected) data back into the system as quickly as possible, keeping business processes running on schedule.
- Standardizing error correction helps provide consistency in the data process, and reporting enables complete transparency into everything that happens to each record.
- Monitoring for unusual activity, e.g. a sudden spike in the volume of incorrect records, can serve as an early warning to larger problems within the process.
- Manually fixing and re-trying rejected records can be very time and resource intensive. Automating as much of the error handling process as possible not only improves data completeness, but frees up resources for tasks which add more business value.
- Aggregate, automated reporting on errors can provide valuable insight. Highlighting lost revenue, or pinpointing problematic sources or systems, are just two benefits of a system designed for managing bad data.
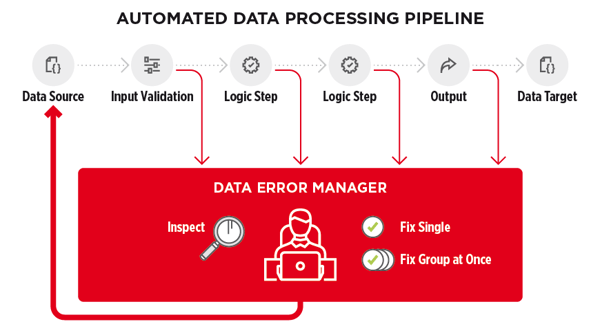
4. Who should be fixing bad data?
It’s easy to think of data errors as the IT departments’ job to fix. But the IT department aren’t the ones that own the data. This can mean that they either don’t have the necessary permissions to alter the data, or by altering it they are bypassing permission structures, potentially leading to security problems.
Not being close to the data means that even if the IT staff have the permissions needed to fix errors, they may not understand it to the same extent as business users do, so lack the necessary knowledge to decide what the fix should be.
The business users are the ones who should be assessing the errors and deciding what the fix should be, so it’s vital to include them in the error handling process.

5. Why is the auditing of bad data important?
Tracking and auditing bad data and rejected records can sometimes be a requirement (for instance in financial companies subject to regulation) but is important for all data processes.
Auditing can help reveal hidden inconsistencies between systems, which can then be addressed and the subsequent data improved, potentially leading to better insight and analysis. Audit trails can also uncover internal fraud or issues within a particular business area, and identify trends that can be used for improvements in business processes across the organization.
Bad data will always exist, but managing for bad data, and architecting systems to handle data errors effectively, can help eliminate unexpected downtime, prevent data loss and avoid operational delays.
Read more about the best practices for designing automated data processing pipelines to take account of bad data. Our whitepaper outlines:
- How to create an effective and sustainable data validation and correction loop.
- Tools and practices that enable business users to effectively identify, correct and manage bad data
- The best ways to effectively control errors
- The importance of reporting in your error handling process
Read more about Data Quality with CloverDX
Share







