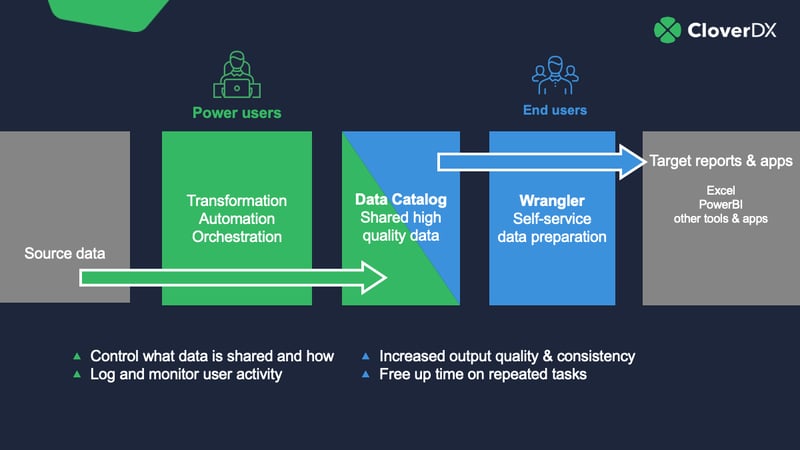
This post is a (lightly edited) transcript of our recent webinar on data democratization, where CloverDX VP Product Branislav Repcek looked at why improving access to data is important, and how you should approach it.
You can read the post below, or watch the video version here:
What is data democratization?
Data democratization can be a loaded term – a lot of people talk about it, but not everyone takes it to mean the same thing.
If we ask Google, we learn that data democratization is an ongoing process of making data accessible and available to a wide range of users, with the goal of providing them with the tools to analyze the data and extract value.

Many organizations today are collecting vast amounts of data, but there’s not always an easy way for people to work with it. The goal of data democratization is to improve that, because as you get more people working with data, you get better value out of it. More people thinking about how to use data effectively means more people making their jobs better and getting better results.
Let’s take a closer look at that definition:
An ongoing process
The data democratization process is not a ‘big bang’ – something you switch on overnight and then it’s done. Partly because your data itself is ongoing – new data comes online, new capabilities are needed, and so on. And partly because it comes down to building a data democratization culture.

Giving everyone a login to your data warehouse is not enough – that’s not going to help them.
You need to build a culture around using and exploring data. People used to working with single applications might not be that effective when they suddenly get data from 200 applications. And that’s not even mentioning the difficulties in just giving everyone access to everything. Regulations, security and relevance all mean you have to think about what data is useful and for who.
Read more about the data democratization features of CloverDXPeople need to be able to explore and use something they need to improve their specific part of the business. Think for example of a marketing team – if they can get access to sales data they can analyze and improve the effectiveness of their campaigns.
The key to implementing this change is to start slowly. If there are a couple of applications that you know are used often, or that data from them is often requested, start there, teach people about it and show them how to use it, and then you can expand.
Accessible data vs silos
Traditional data structures keep data in silos. Think of a CRM or ERP system that only people in certain departments have access to. There could be dozens or even hundreds of systems built for a specific purpose.
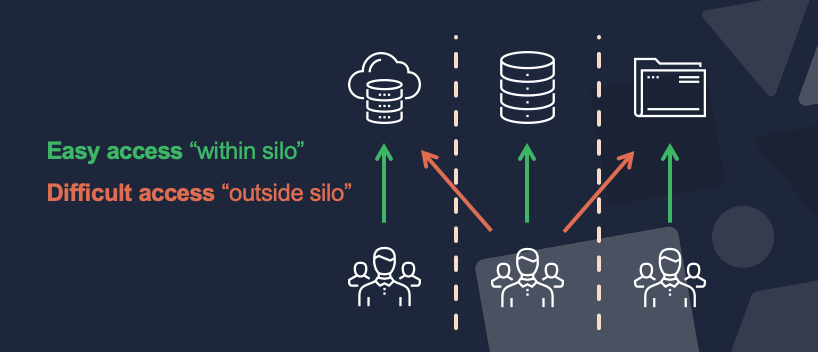
Going outside of the silo is difficult. Data you don't have access to is invisible to you, and you have to know what to ask for. Often this means long discussions about what is even available and how to get the data to you, and these discussions often end up with security concerns (‘Why would anyone other than Finance need access to invoices? That’s not allowed…’)
But even if you overcome these concerns, giving access isn’t that simple. You could just give everyone an account in that app, right? But that can just make things worse. People now have access, but they often don’t understand what they’re looking at. Users just want to be able to work with the data, they don’t want to have to learn how hundreds of applications work, or what the data model is.
One way of handling this is a data catalog, something between applications and users. A data catalog is a layer that gives access to certain users to certain data and that helps users understand what is in the data and how to use it, without having to log into an unfamiliar system and UI.
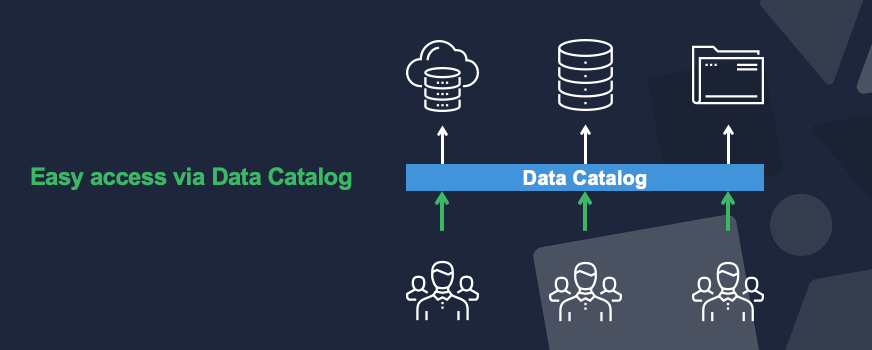
But what if you have a data lake or a warehouse? You still need a place where users can search metadata, and not everyone is familiar with SQL to work with a warehouse directly.
Collaborate to build it better
One of the keys to implementing a data democratization strategy is collaboration. All parts of the organization need to work together to agree on what to publish, how, and to who. There’s people that want to have access to the data, there’s people that own the data, and there’s someone in the middle (typically IT) that needs to make it happen. All of these teams need to work together to be effective in making data accessible.
Again, the key is to start small. There’s usually some datasets that are used daily, so it’s generally a good idea to start with these popular ones, and get users used to having access to this data and working with it.
Once they get into the habit of doing that, you can add more datasets for people to access. And it’s important to think scalably – so when someone comes to the IT team to ask for a new dataset, you can either publish it so everyone has access, or if you need to create a new dataset (because it’s not something already directly available), you apply transformations and publish that, so you don’t need to recreate it the next time someone asks.
Trusted data
As the team responsible for publishing data, you also need to be responsible for publishing quality data that can be trusted. Especially if you’re working with an old system, or something where data has been entered by hand, chances are it’s going to need some work to be usable.
If you need to apply data cleansing or transformations to data to get what users are asking for, you want to do this at the source, so you don’t have to do it every time someone asks.
This is part of the collaboration process. You as the data provider need to understand what users need the data for, so you can tailor it for them, even if it means creating different versions of the data for different users. If you have an index that’s searchable people can always find the version of the dataset that has the columns they need and so on.
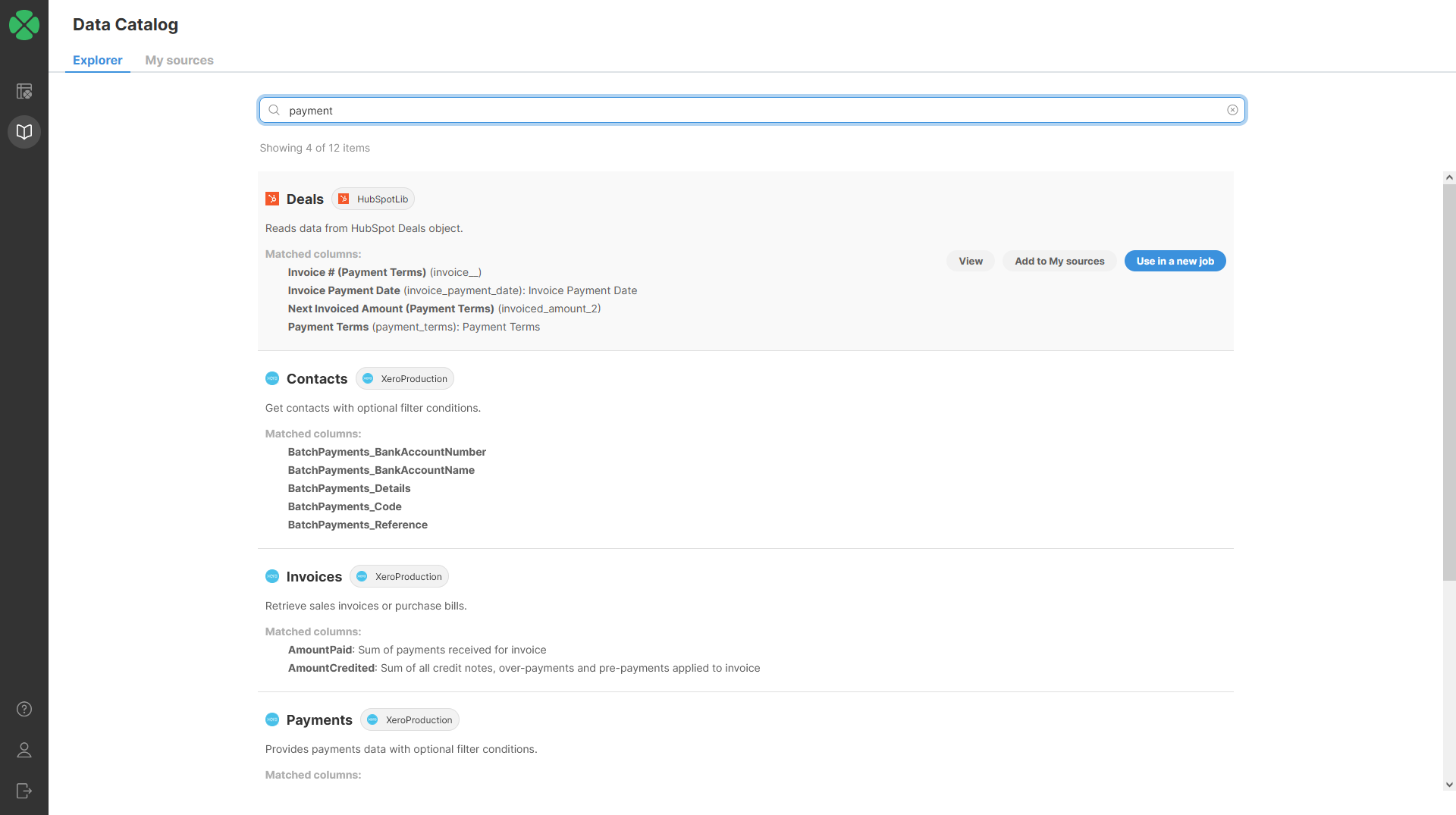
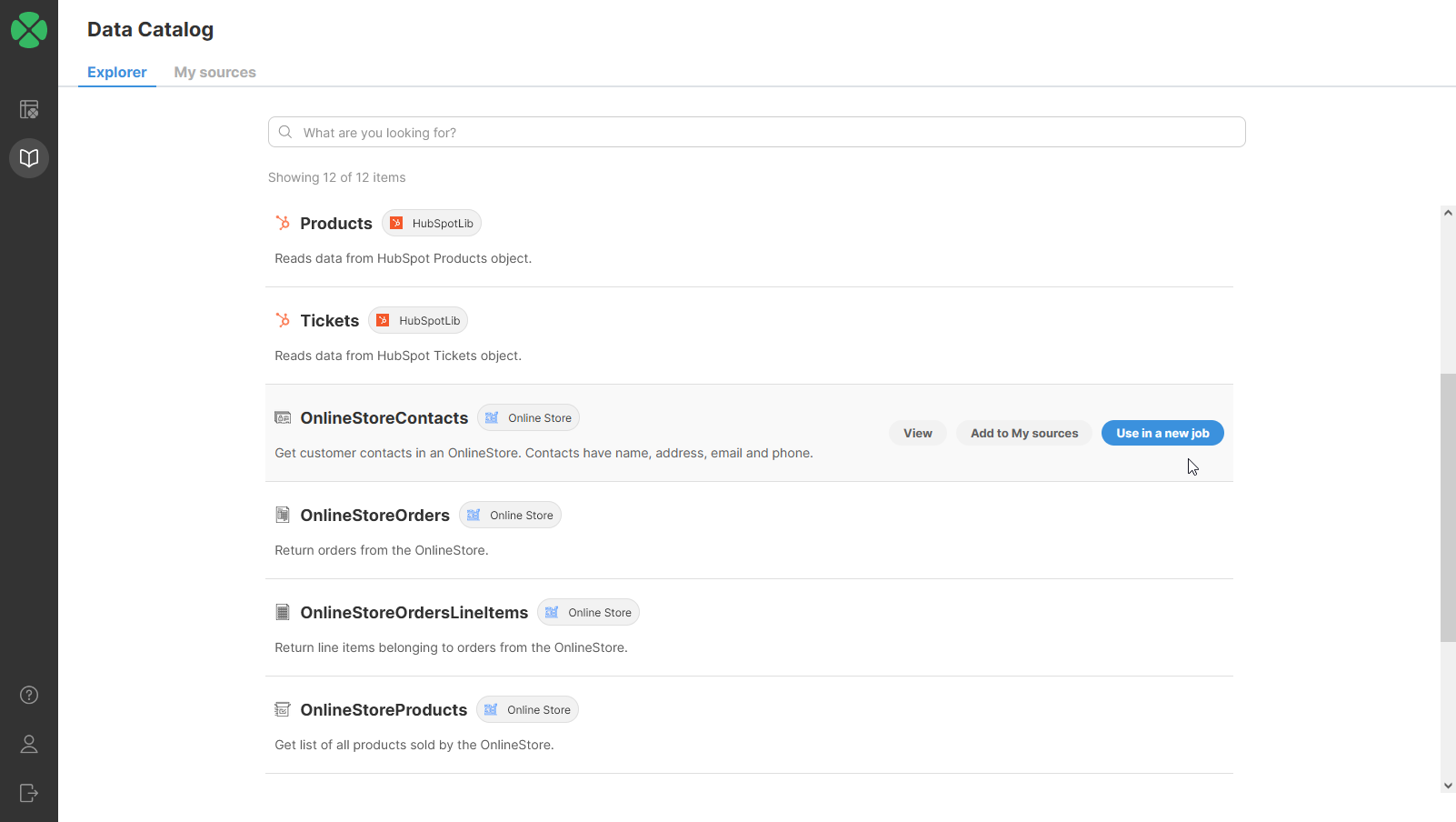
Search results in the CloverDX Data Catalog
Provide tools for your users
Data on its own is not very useful if you don’t have the tools to work with it. Some teams may be used to using tools such as PowerBI or databases already, some less-technical users might not be.
You should allow people to work with specialized tools they already have, but also standardize on some common tools that help teams that want to work with data in a lighter way. If you just let everyone pick a tool, you’ll end up with a proliferation that can be hard to manage.
Making data useful to people also means publishing it in a common format that everyone can use, no matter what the tool or platform they’re working with.
How CloverDX helps provide self-service data
The CloverDX data management platform is built on automation. The more you can automate as much of your data workflow as possible, the faster you can get accurate data into the hands of people who need it.
CloverDX’s data democratization features are designed to bridge the gap between what the IT team creates and what business users need. Highly technical users can design, automate and operate complex data pipelines, and publish the results – in whatever format that’s needed – to the people (or applications) that need it, without those users needing to understand a complex tool or learn code.
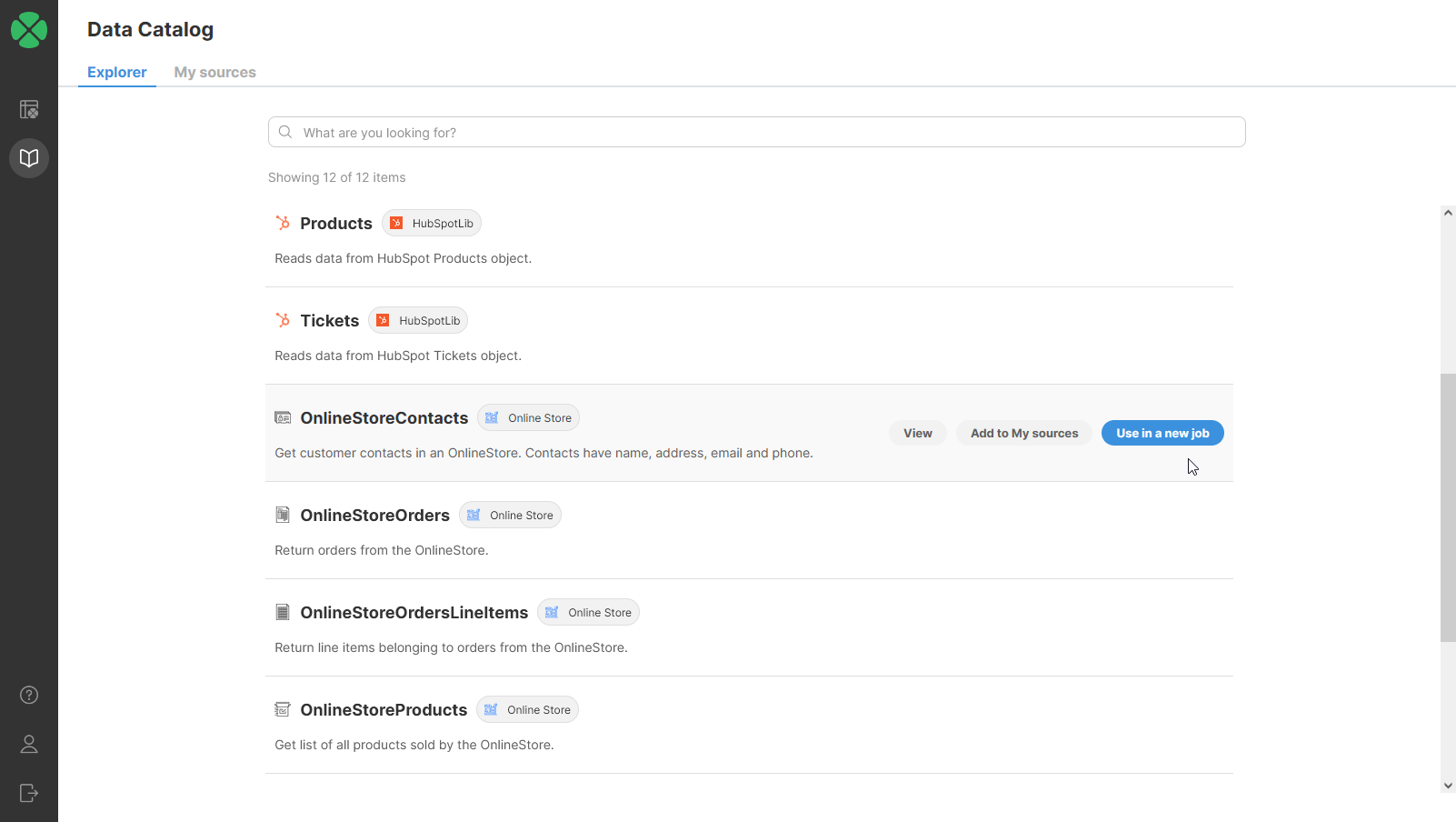
The CloverDX Data Catalog interface
The Data Catalog allows you to expose live data to users in a simple, searchable, understandable interface. As well as just publishing raw data as stored in a database, you can also attach business logic to it in a CloverDX workflow so you can create new datasets for users to access – think for example of a dataset of sales employees by revenue, created from tables in the accounting system and CRM.
The ability to incorporate business logic also allows you to make sure data is clean, prepared and ready for use, saving time and increasing productivity of your users.
Some of the benefits of using the CloverDX Data Catalog to make prepared data available to users include:
- Saving time: No need for users to waste time filtering the entire dataset to show just the value or date ranges they need (especially useful when you’re preparing a report every month, week, or day).
- Reducing errors: No chance of human error when preparing data, e.g. selecting the right list of countries for an EMEA report.
- Standardized definitions: Everyone in the organization can access the ‘Active Users’ report, for example, without everyone using their own definition of what ‘Active’ really means.
- Live data, every time: Because the data is direct from the source, reports are always up-to-date, every time you click ‘run’.
- Better quality data, across the business: When everyone is using the same datasets, it’s easier for someone to spot a mistake or opportunity for improvement and work with IT to fix it at source, so other users going forward are now using the corrected data.
Data democratization is enabling organizations to unlock the full potential of their data and foster collaboration in the process, providing users from both IT and business teams the ability to find, explore, and analyze data without sacrificing quality. CloverDX helps break through data silos and give all users, regardless of their technical ability, access to data sources that they can search, explore and work with.
If you’re interested in learning more about how CloverDX can help your business achieve greater success through data democratization, request a demo and see how you can make data available more easily, while still keeping centralized control.
Share