Getting confused with all the different terms for big data storage? Ninety percent of business leaders cite data literacy as key to company success, but only 25 percent of workers feel confident in their data skills. With all the different terms floating around, it’s difficult to keep track of what different data storage types are, and how they’re used.
Let’s take a look at two of the most popular data storage solutions and explore their key differences.
Data warehouses
When you think of a warehouse, you probably imagine several rows of high shelves carefully piled with stock. Everything’s labelled, everything’s in its place. This makes it straightforward for staff to come along and pick the items they need.
The key here is the structure. Data warehouses operate in much the same way.
What are data warehouses?
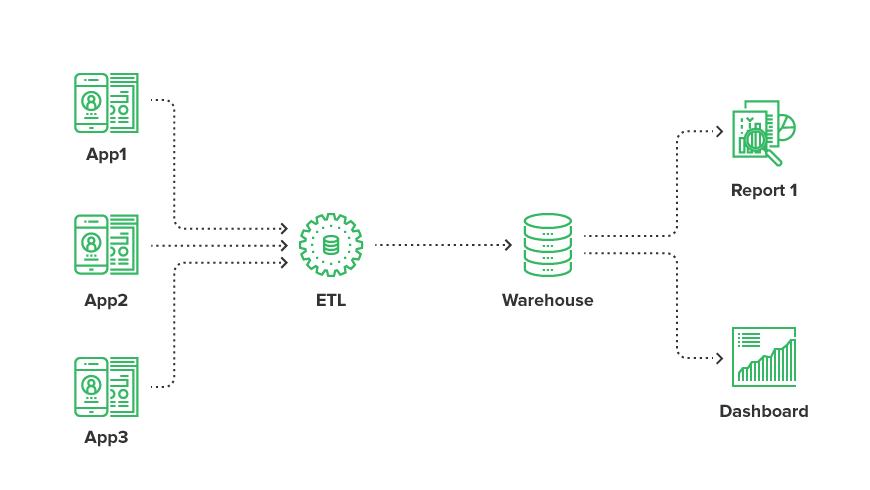
Data warehouses are a consolidated repository for storing your data assets. It’s a large collection of data that’s organized to help you make decisions. Usually, for businesses, data warehouses harvest the data that come from internal applications. This might be sales, marketing, or financial data.
Commonly, data warehouses help to answer business-related questions with a consolidated source of data. You might want to find out how many of your products were purchased over a selected timescale, or perhaps products purchased from certain countries. The data warehouses marry up the end-user data with the questions you want to answer.
What are the benefits?
This approach equips you with a reliable and well-tried source of business intelligence that you can constantly build upon.
Here are some more advantages of using a data warehouse:
- Answers questions quickly. If you run into a problem and need some analytics, you can easily run queries through your data warehouse. It’ll quickly draw upon the relevant data and produce what you’re looking for without fuss.
- Tracks data over a long period. As you’ve got structured data from many different internal sources, you can easily create reliable business intelligence over a long period of time. There’s very little guess-work, allowing you to analyze current data against historical trends
- Highly accurate. Consolidated data means pinpoint accuracy. You’re not muddling up different data types that result in a skewed answer to your question.
- Cheap to build. Modern data warehouses keep costs low, especially in the era of cloud computing.

Recently, organizations have started moving to the ELT approach (extract, load, transform). This involves using an ELT tool (such as CloverDX) to extract the data and load it into a data warehouse. There, it is then transformed, taking advantage of the database to do the hard transformation work. This means you’re performing the expensive part with a system that has the resources.
Data lakes
Just like natural lakes, data lakes are filled with a whole host of unstructured and unrefined components. But, what makes them good for data storage?
What are data lakes?
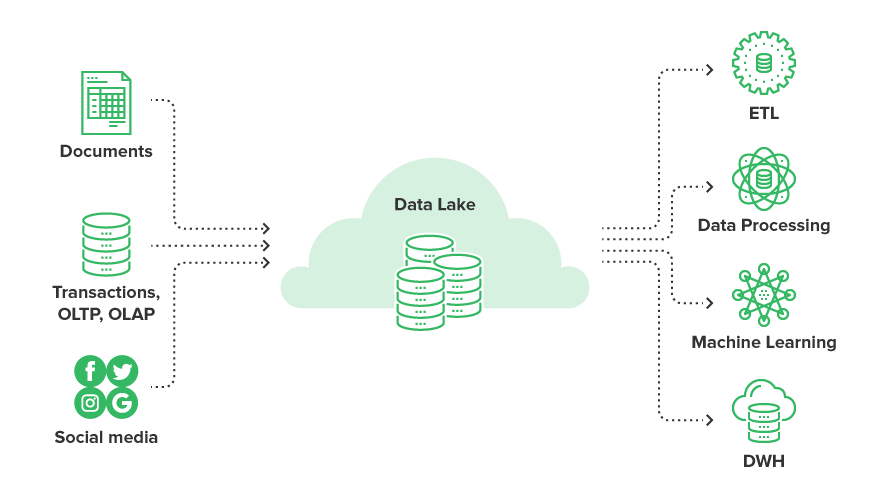
A data lake is a methodology for storing large amounts of raw data in a single repository. They’re unstructured and typically combine several different data formats.

The raw data remains in the lake until it’s needed. Only then is it transformed into the correct format to extract valuable insights. Think of it like unrefined ore from a mine. You can only get at the precious metal inside once it’s smelted.
Data lakes can be both structured and unstructured, and store all your data at any scale. As companies struggle to keep up with increasing data complexity, data lakes allow them to fill a repository with whatever data they have, and refine it as and when they need.
The main purpose, therefore, is to have any and all data available in one place. That way, your data teams can provide insights on a business problem or value proposition. Data lake use cases usually revolve around reporting, visualization, analytics, and machine learning.
What are the benefits?
Data lakes are your one-stop shop for data storage. Everything’s bobbing around together in a big pool. So, when questions arise, you’ve got the data to solve them. Here are more benefits of data lakes:
- Gives an organization a place to store any data they have. Regardless of what data you’re looking to store, you can deposit it in a data lake. The storing process is quick and easy as you don’t have to restructure any existing data.
- All data is readily available. Data lakes don’t exclude any data formats. Regardless of the issue you have, you can access the data you need right from the get-go, without having to sort through the structure.
- Based on low-cost distribution platforms. Storing data in large repositories is far more cost-effective than paying for structured data warehouses. Built using low-cost distribution platforms, data lakes aren’t going to rack up your usage bills.
- Low entry investment. The initial investment of data lakes, when compared to other options, is inexpensive.
That said, there are some things to look out for when using data lakes. With all your data dumped into one repository, it’s all too easy to let it turn into a data graveyard. You don’t want to simply leave it hoping that you might use it one day in the future.
What are the main differences?
Both data warehouses and data lakes are widely used. The key differences surround how you want to store the data, what its purpose is, and how end-users access it.
Let’s break it down to see how they differ in more detail.
Purpose
Data warehouses only store data that’s assigned a specific purpose. It’s structured and refined. Data lakes on the other hand are a repository of different pieces of data that are yet to get a fixed use. The lake fills up with raw data, often without a purpose in mind.
Data structure
As we’ve explored, data warehouses store structured and refined data, kept neatly in the right place. Data lakes use raw data, unrefined and unassigned. You can mold data for uses (such as machine learning) but it’s not organized in any fashion.
Who are the end-users?
You’ve got to consider who’s going to be looking to use the data, and what their skill level is in dealing with it. Data warehouses allow end-users to extract the data they need and use it in visual reporting, such as tables and charts.
Raw data takes more expertise to work with. You’ll need data analysts and scientists who have the right know-how and tools on hand.
Which one should you use?
When it comes down to choosing data storage for your business, it’s worth noting that one methodology is not necessarily better than the other. And, it is possible to run a combination of the two.
They are both suited to different requirements. This means you’ll have to analyze your requirements, needs and budgets to choose the one that’s right for you.
Learn more about data architecture in our Guide to Enterprise Data Architecture.

Share