Running data processes with scripts, Excel, or custom applications is very common. But there often comes a point where you need more reliability in your data pipelines - and your developers need to be spending less time on maintenance and troubleshooting.
Drawbacks of homegrown ETL solutions (or why you shouldn’t be using Excel to run your data processes)
There’s usually 3 main approaches to building your own ETL solution.
1. Excel
Excel: the way things often start out. It has its advantages – it can be very powerful in the right hands, and it’s approachable by a lot of non-technical users. But it also has limitations:
- It can be a ‘black box’. It’s often the case that one technically-skilled person has built complex queries or processes and they’re the only ones who really understand how it works. It’s not transparent for any other users, and leaves the business exposed to risk if that person leaves the company.
- You can hit technical limitations. Excel is a powerful data tool, but it’s never going to be as flexible or reliable as something custom built for complex data pipelines.
- Error-handling is difficult. The lack of transparency in what’s happening to the data also means it’s time-consuming to identify where problems have occurred, and difficult to build automated processes to handle errors.
- It’s hard to automate. The goal of data pipelines is to automate as much as possible, and with Excel it’s just not possible to build full end-to-end processes that include things like monitoring and reporting.
- Performance becomes an issue at scale. As your data needs grow – in either volume or complexity – Excel will struggle. Which can be a particular problem if you’re relying on time-sensitive data.

2. Scripting
Scripted solutions often start out as something simple. And they can be a perfectly adequate solution if all you need from your data processes is something very simple.
But the situation we see more often is that a ‘simple’ script often balloons to an unreliable, difficult-to-maintain mess and you can quickly end up with small bits of code and complex scripts with lots of libraries and dependencies behind them. The problems here include:
- It’s not a holistic approach to advancing data strategy. There’s often a lack of overarching vision and how things fit together.
- The approach is often one of adding to scripts, not refactoring. When things break, the fix is often a scotch-tape solution, which doesn’t make for a solid foundation for data infrastructure.
- A single developer is often a single point of failure in a process. And relying on one person creates a risk to the business.
- Scattered developer skillsets (SQL, Python, Shell scripts…) lead to a lack of consistency.
- Libraries and dependencies often become unsupported or deprecated over time, leading to more ad-hoc fixes.
3. Building a custom application
The other option for building your own data solution is to build an entire application in-house. This is often seen either in companies that think they are too small to afford to buy a solution, or alternatively, in companies that are so big that they have the (often large) budgets and resources to custom-build what they need. For the latter, a custom application can be best solution – you get exactly what you need, and full control over it. But for everyone else, it can have unforeseen consequences such as:
- Something that starts with a limited scope can easily grow over time. Ironically, ‘successful’ applications can often cause the most headaches as more and more people in the organization start to use it and make their own requirements.
- It often requires a dedicated team of developers to maintain, manage and to implement new requirements
- Support needs are often forgotten about. Especially when things start small, the support needs such as user management, monitoring, and reporting are often forgotten about until they become urgent (and then need even more developers to build and maintain something that you’d get out-of-the-box with a commercial platform).
Signs you're ready to upgrade your data processes
How do you know when you should start looking to move on from script-based ETL processes? There’s no right answer, and the process of buying an off-the-shelf platform can take time and resource to do right. But if you’re encountering any of the symptoms below with your data processes, then time and effort spent now on evaluating whether a robust, reliable platform is right for you could start paying off immediately.
- You’re spending a lot of time and effort on existing scripts and processes. You’re spending more and more time on maintenance and fixing errors, and not enough on improvements or innovation.
- Notes such as ‘This was written by Steve – don’t touch it!’ And now Steve has left the company, leaving his script as a core part of some business-critical process, and everyone is too afraid to touch it in case it breaks.
- It’s preventing you from upgrading other systems, e.g. implementing a new BI tool
- More people need to use it. As more people rely on a process, you’ll have to deal with more requests for functionality, and more maintenance
- You need to scale. Whether it’s because:
- Your data volume or complexity is increasing
- You need to do more with less resource
- Your reliability needs increase – as more things become reliant on the process and your data, it becomes more business critical to keep everything accurate, reliable, auditable and time-sensitive

Benefits of a data platform
Investing in a data platform can save you time and money, and make your data processes more reliable and easier to manage. Here are just some of the benefits you could see with a solid data foundation:
Free up resource and save cost
A modern data integration platform can enable you to do more with less. The right platform can help you:
- Develop faster: Processes and components designed to be reusable, repeatable and shareable mean users don’t have to reinvent the wheel on every project.
- Free up engineer time: A platform that gives you better transparency, and business-friendly interfaces, can mean that less technical people can do work that previously only highly technical users could do.
- Spend less time on maintenance and management: Platforms that come with monitoring, reporting and user management out-of-the-box mean you don’t have to spend time building (and updating) your own systems. Plus, if something breaks, there’s someone on the end of the phone to fix it.
- Run things at the click of a button: Build end-to-end automation, including triggering jobs automatically based on schedules or triggers, saving time and increasing accuracy and reliability.
Faster troubleshooting
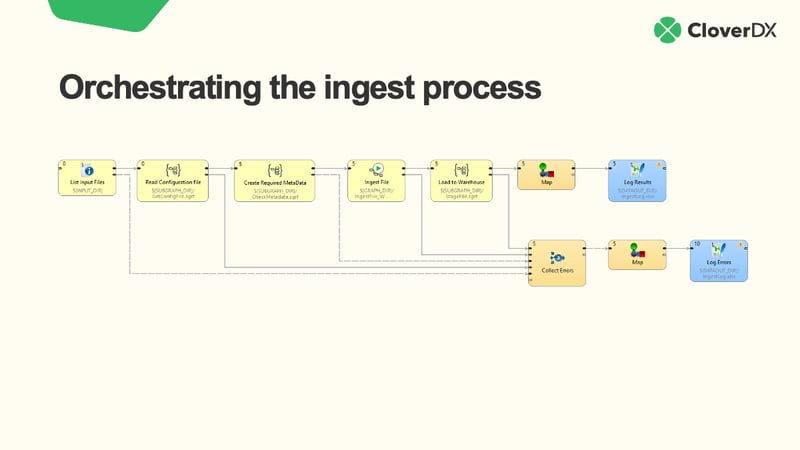
Rather than having to trawl through pages of code to find where a problem occurred, a visual interface for data workflows can help you easily see errors. Plus, the ability to configure proactive notifications for errors mean you can resolve issues quickly, minimizing downtime and improving performance.
Eliminate reliance on ‘the one person who understands it’
A shared, transparent platform removes the business risk of all the knowledge being in the head of one technically-skilled employee.
A platform with a visual interface gives you clear visibility into data workflows – so everyone can see what’s happening with your data – and helps collaboration across the organization.
"What we really like is that we have a very visual way of showing our process, debugging our process and understanding what’s going on without having to do everything in command line or some text-based piece of code.”
- Ortec Finance
Scalability
A modern, scalable data integration platform enables you to handle all the data sources you need (whether on-premise, in cloud, or both), and to scale capacity, without any extra effort.
And no matter how many data pipelines you’re running, centralized monitoring, auditing and reporting gives you a control center for all your processes.
Keen to learn more? Download the guide to Cracking the Build vs Buy Dilemma for Data Integration Sofware.

Share